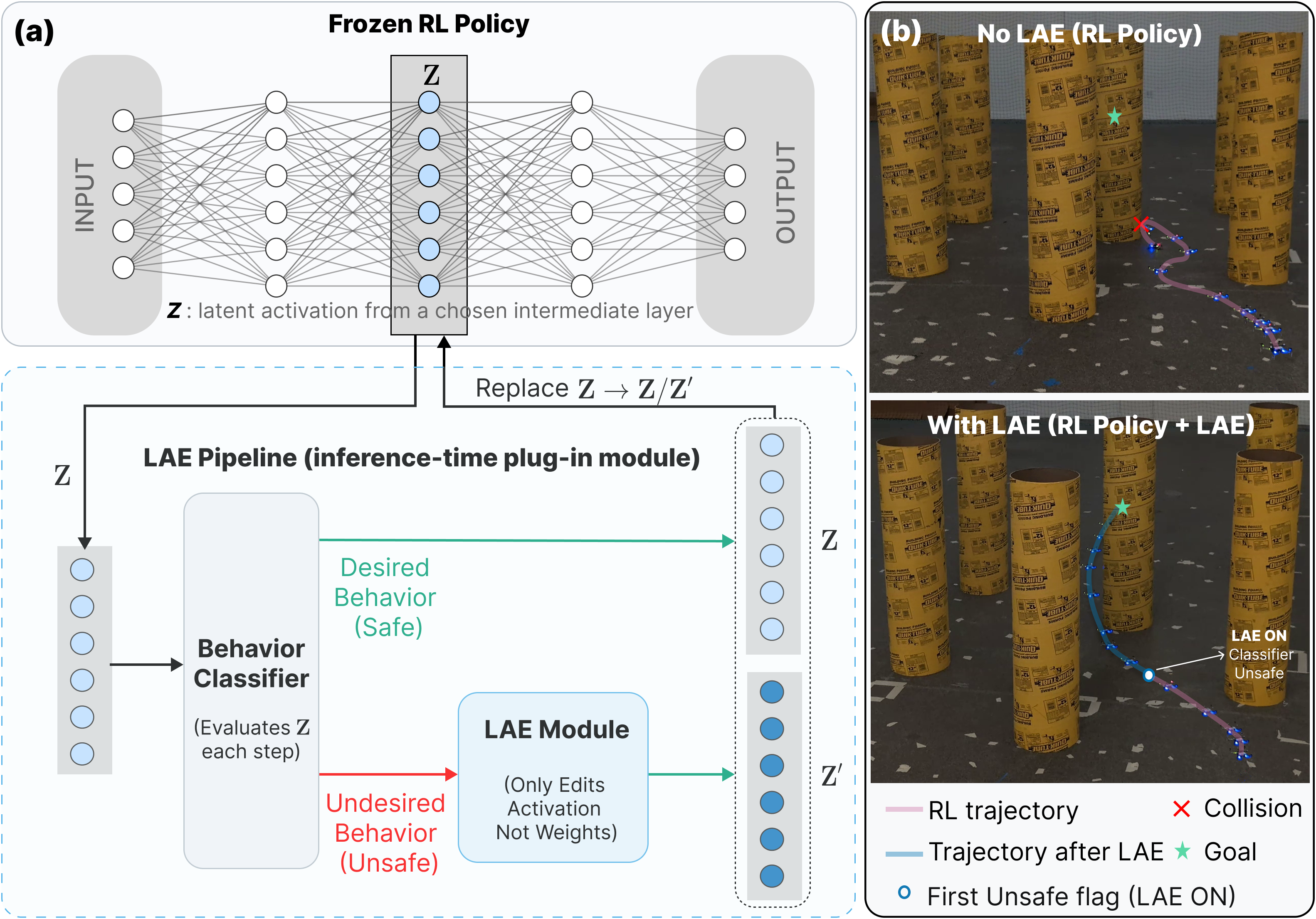
(a) Conceptual overview of LAE.
A behavior classifier monitors the intermediate latent activation Z of a frozen RL policy.
Safe activations pass unchanged, while unsafe ones are replaced with edited surrogates Z′
generated by the activation editing module, without modifying policy weights.
(b) Real-world quadrotor navigation.
Without LAE, the RL policy collides with an obstacle. With LAE, the trajectory follows the
base policy until the first unsafe flag, after which successive latent edits steer the
quadrotor away from the unsafe zone, enabling it to reach the goal safely.
Abstract
Reinforcement learning has enabled significant progress in complex domains such as coordinating and navigating multiple quadrotors.
However, even well-trained policies remain vulnerable to collisions in obstacle-rich environments.
Addressing these infrequent but critical safety failures through retraining or fine-tuning is costly and risks degrading previously learned skills.
Inspired by activation steering in large language models and latent editing in computer vision, we introduce a framework for inference-time Latent Activation Editing (LAE) that refines the behavior of pre-trained policies without modifying their weights or architecture.
The framework operates in two stages: (i) an online classifier monitors intermediate activations to detect states associated with undesired behaviors, and (ii) an activation editing module that selectively modifies flagged activations to shift the policy towards safer regimes. In this work, we focus on improving safety in multi-quadrotor navigation.
We hypothesize that amplifying a policy's internal perception of risk can induce safer behaviors. We instantiate this idea through a latent collision world model trained to predict future pre-collision activations, thereby prompting earlier and more cautious avoidance responses.
Extensive simulations and real-world Crazyflie experiments demonstrate that LAE achieves statistically significant reduction in collisions (nearly 90% fewer cumulative collisions compared to the unedited baseline) and substantially increases the fraction of collision-free trajectories, while preserving task completion.
More broadly, our results establish LAE as a lightweight paradigm, feasible on resource-constrained hardware, for post-deployment refinement of learned robot policies.
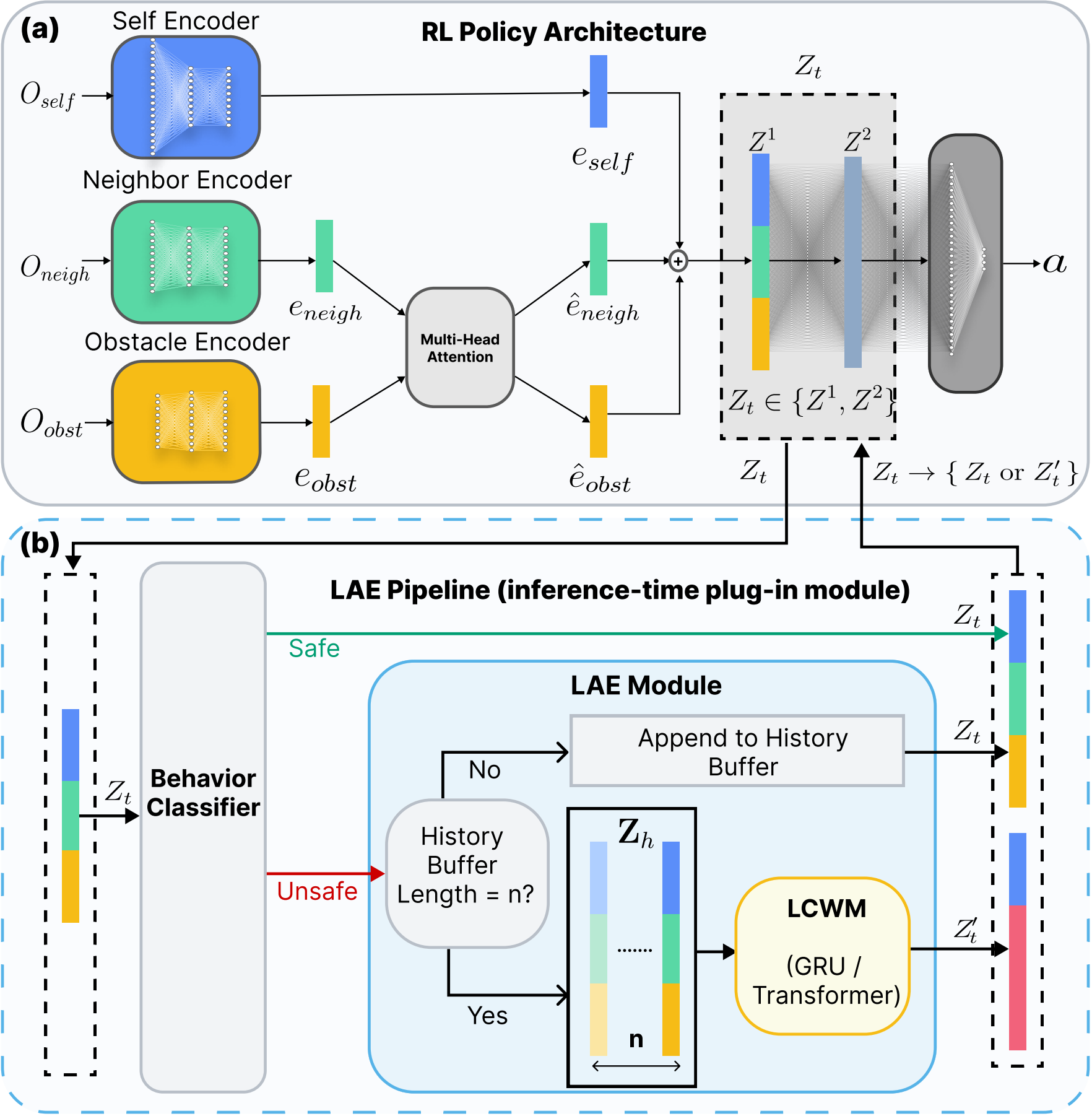
Method Overview
Latent Activation Editing (LAE) is an inference-time safety layer that intervenes at a chosen
intermediate latent representation Zt inside a frozen reinforcement learning policy.
A lightweight behavior classifier continuously monitors these activations and detects states
associated with unsafe behavior. When an unsafe latent is detected,
LAE replaces Zt with an edited surrogate activation Zt′, after which the policy
continues forward normally without any modification to its weights.
In our implementation, the editor is realized using a
Latent Collision World Model (LCWM), which predicts future collision-related latent activations
from a short history buffer. By amplifying the policy’s internal perception of risk, the edited
latent encourages earlier and safer avoidance maneuvers while preserving the policy’s original
goal-directed behavior.
Overview of LAE integrated on a pre-trained multi-quadrotor navigation policy.
(a) RL policy architecture: observations are encoded and fused via multi-head attention
to produce intermediate latent activations (Z¹, Z²), which serve as candidates for
Zt.
(b) Editing pipeline: a behavior classifier evaluates latent activation
Zt and forwards it unchanged if safe, or routes it to the editing module if
unsafe. The module maintains a short history buffer and, once filled, invokes the
LCWM to generate a surrogate Zt′ that replaces the unsafe latent activation
Zt.
No retraining: policy weights remain frozen; edits occur only at inference-time.
Selective intervention: trajectories match the base policy until an unsafe latent is detected.
Modular & reversible: the editor can be enabled/disabled without re-optimizing the policy.
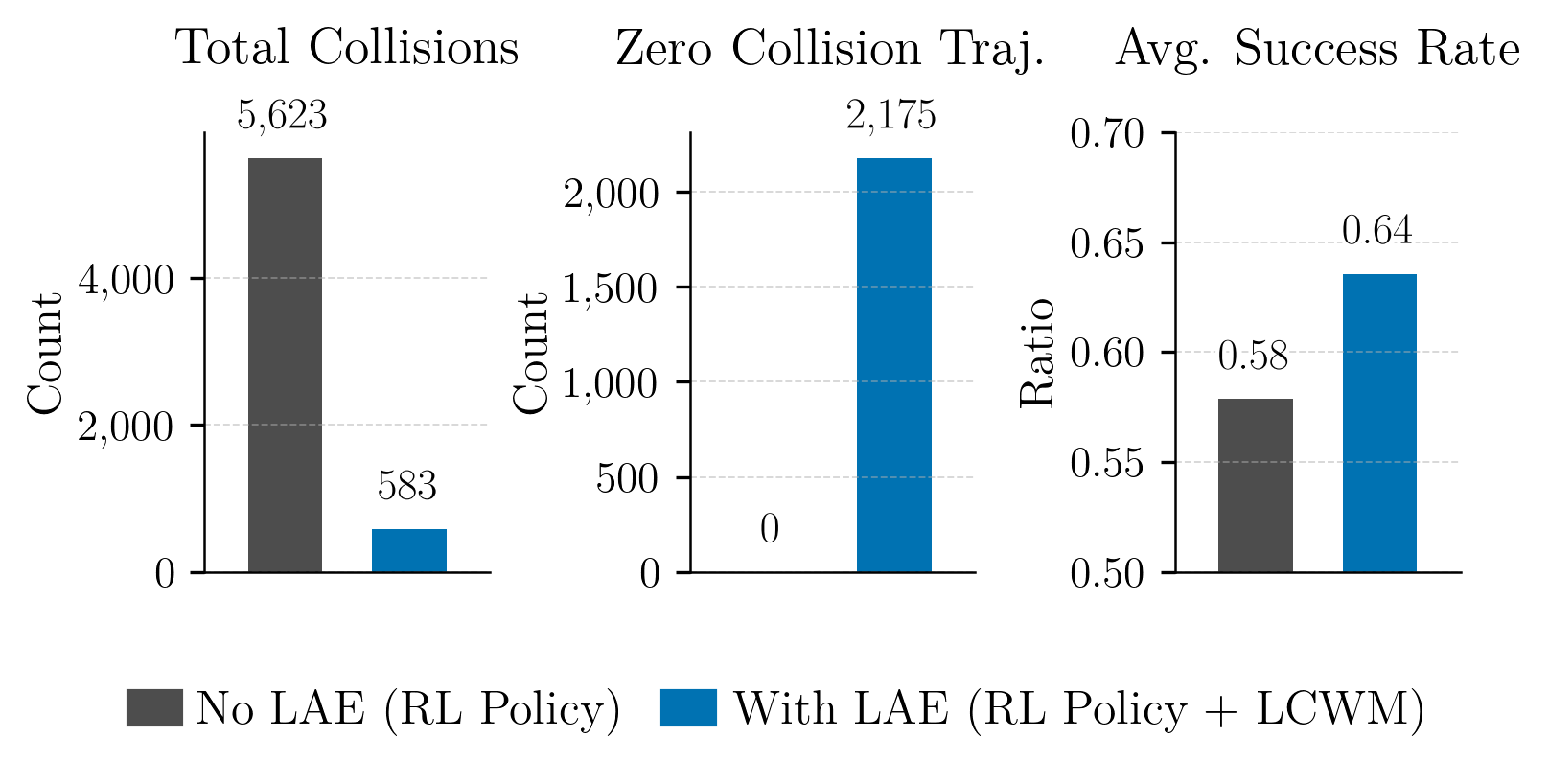
Simulation Results
We evaluate LAE in large-scale simulation and real-world Crazyflie experiments in obstacle-rich indoor environments.
LAE substantially reduces collisions while preserving task success, and maintains identical behavior to the base policy in safe regions.
Quantitative comparison of the base RL policy with and without LAE on 2,600 environmental configurations. We report total collisions, zero collision trajectories, and average success rate.
No LAE (Base RL Policy).
With LAE (RL Policy + LAE).
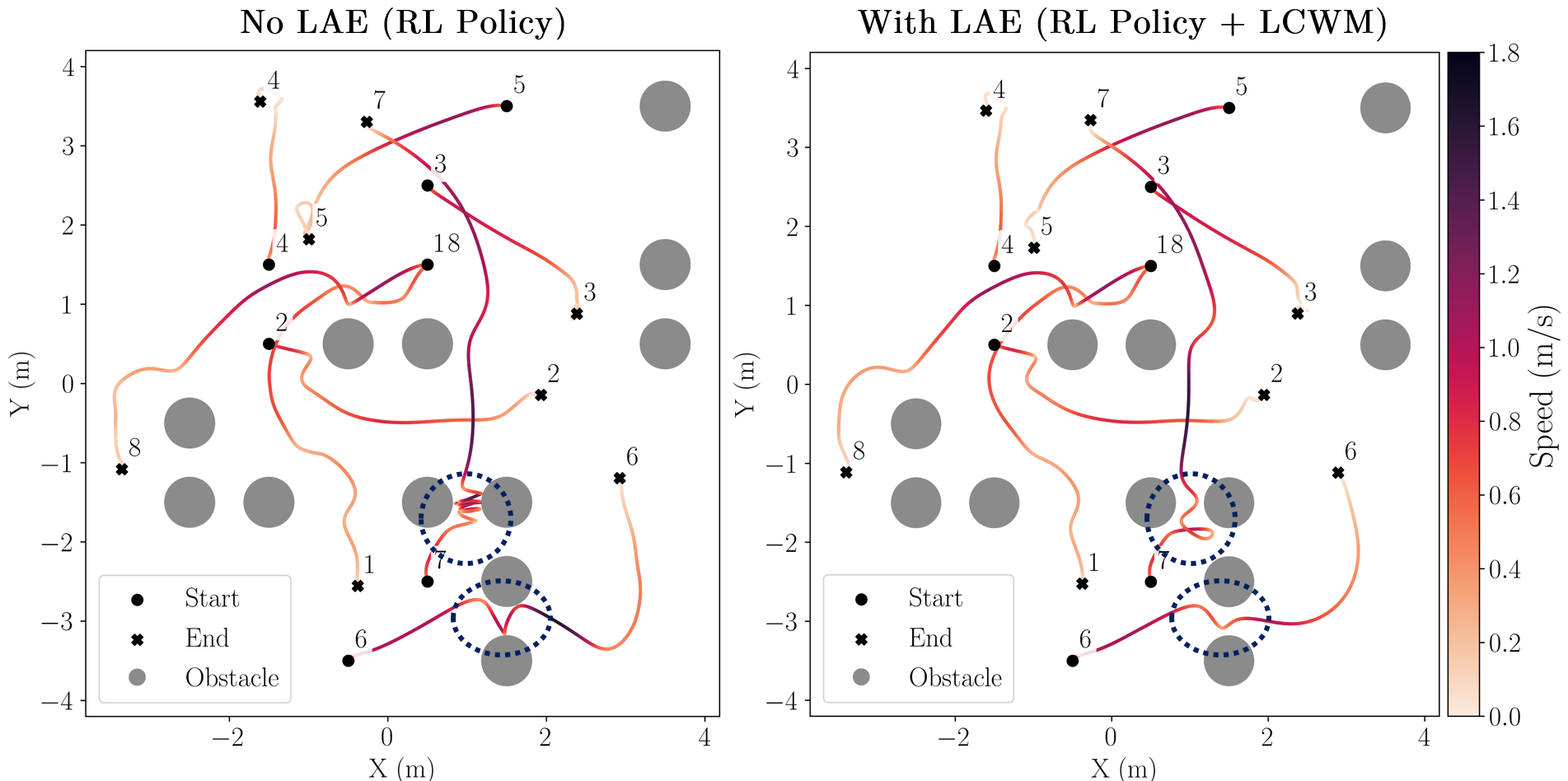
Representative trajectory comparison.
Left: base RL policy (no LAE), which collides with obstacles. Right: RL policy with LAE, which avoids collisions while remaining identical to the base policy in safe regions and still reaching the goals.
Trajectories are coloured by speed. Numbers denote quadrotor index.
Real-World Videos
Real World Experiment: Single Drone Navigation in Cluttered Enviornment
Real World Experiment: Multi-Drone Four-Way Crossing Task
No LAE (Base RL Policy).
With LAE (RL Policy + LAE).
BibTeX
@misc{das2025latentactivationeditinginferencetime,
title={Latent Activation Editing: Inference-Time Refinement of Learned Policies for Safer Multirobot Navigation},
author={Satyajeet Das and Darren Chiu and Zhehui Huang and Lars Lindemann and Gaurav S. Sukhatme},
year={2025},
eprint={2509.20623},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2509.20623}
}